
大模子选型绝非简便的性能对比赛,而是关乎产物成败的策略决策。从任务类型到资本抑制,从工程化落地到风险遮掩,一套严谨的选型门径论正在成为AI产物司理的中枢竞争力。本文深度拆解场景适配、模子对比、资本核算、部署考证四大关键维度,助你在口试和实战中作念出精确判断。

口试AI产物司理,10个口试官有9个会问这个问题:
“若是让你给咱们的产物选一个大模子,你会怎样作念?”
好多东谈主一上来就说:
“我会选GPT-5.4,因为它最强”,或者“我会选Qwen3.5,因为它开源免费”。
若是你是这种回话,那平直就凉了。
因为大模子选型根柢不是“谁强选谁”这样简便。
它是一个系统工程,需要玄虚探究场景、性能、资本、工程化、风险等多个维度。
底下先容一套大模子选型门径论,岂论是口试照旧本色责任,齐能用得上。
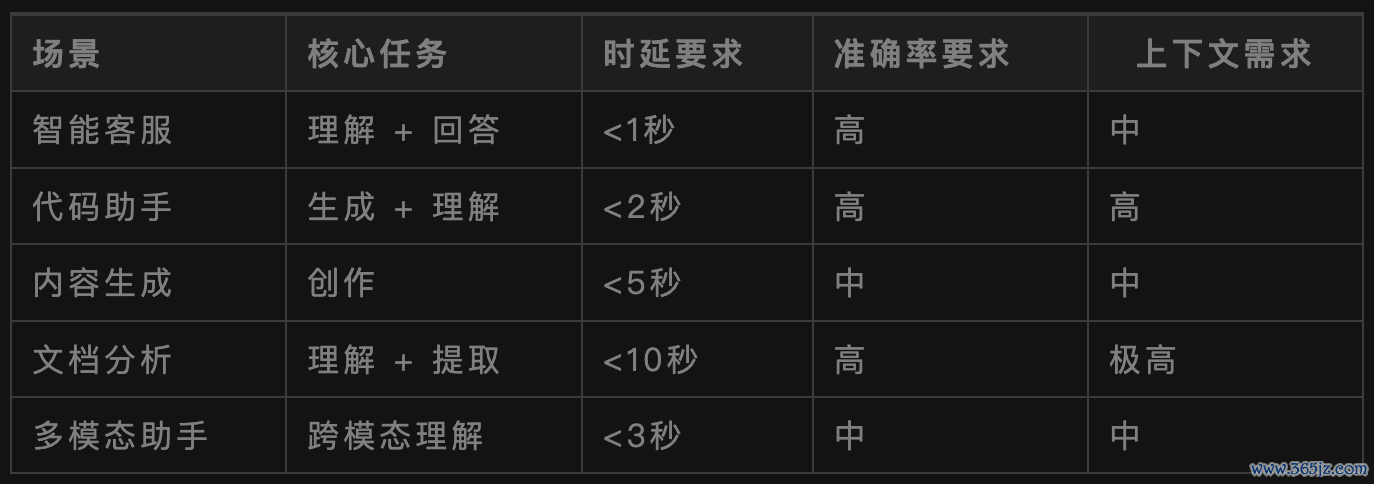
01先搞明晰你的场景到底需要什么
这是最容易被忽略,但亦然最费劲的一步。
好多东谈主上来就对比模子参数,这十足是背本就末。
记取:莫得最佳的模子,只须最符合你场景的模子。
你需要从三个维度拆解你的场景需求:
1、任务类型:生成、说明照旧多模态?
不同的任务对模子智力的条目迥乎不同。
生成类任务对模子的创造力和流通度条目高,比如写案牍、写代码、写阐发。
说明类任务对模子的准确性和逻辑性条目高,比如分类、索求、追想、问答。
多模态任务需要模子具备跨模态说明智力,比如图文说明、视频分析、语音交互。
举个例子:
若是你要作念一个智能客服,中枢任务是说明用户问题并给出准确谜底。
那么你应该优先聘请说明智力强的模子,而不是生成智力强的模子。
2、性能贪图:延时、准确率、安全
这三个贪图是产物体验的中枢,必须量化。
实时交互场景,如聊天机器东谈主,条目延时
非实时场景,如阐发生成,不错接收几秒以致几十秒的延时。
不同场景瞄准确率的条目不同。
比如医疗会诊场景条目准确率>99%,而豪迈聊天场景80%的准确率就不错接收。
金融、医疗、政务等明锐场景对内容安全条目极高,必须严格扫视无益内容生成。
3、输入输出:文本长度、多言语维持
若是你的产物需要措置长文档(如条约、论文),那么模子的凹凸文窗口大小就异常费劲。
当今主流模子的凹凸文窗口还是达到了256K-1MTokens。
若是你的产物面向环球用户,那么需要聘请多言语智力强的模子。
我给你一个简便的表格,帮你快速判断不同场景的中枢需求:
02模子参数与性能对比
搞明晰需求之后,就不错启动筛选模子了。
主流大模子不错分为两大类:闭源API模子和开源模子。
1、主流闭源模子对比
闭源模子的上风是开箱即用、性能厚实、更新实时。
漏洞是资本高、数据不安全、定制化智力有限。
当今环球顶级闭源模子有四个:
OpenAIGPT-5.4Pro、AnthropicClaudeOpus4.7、GoogleGemini3.1Pro、字节高出DoubaoSeed2.0Pro。
国产旗舰闭源模子有:
通义千问3.6Plus、文心一言5.0、GLM-5.1。
底下整理了2026年Q1各大模子性能对比数据:
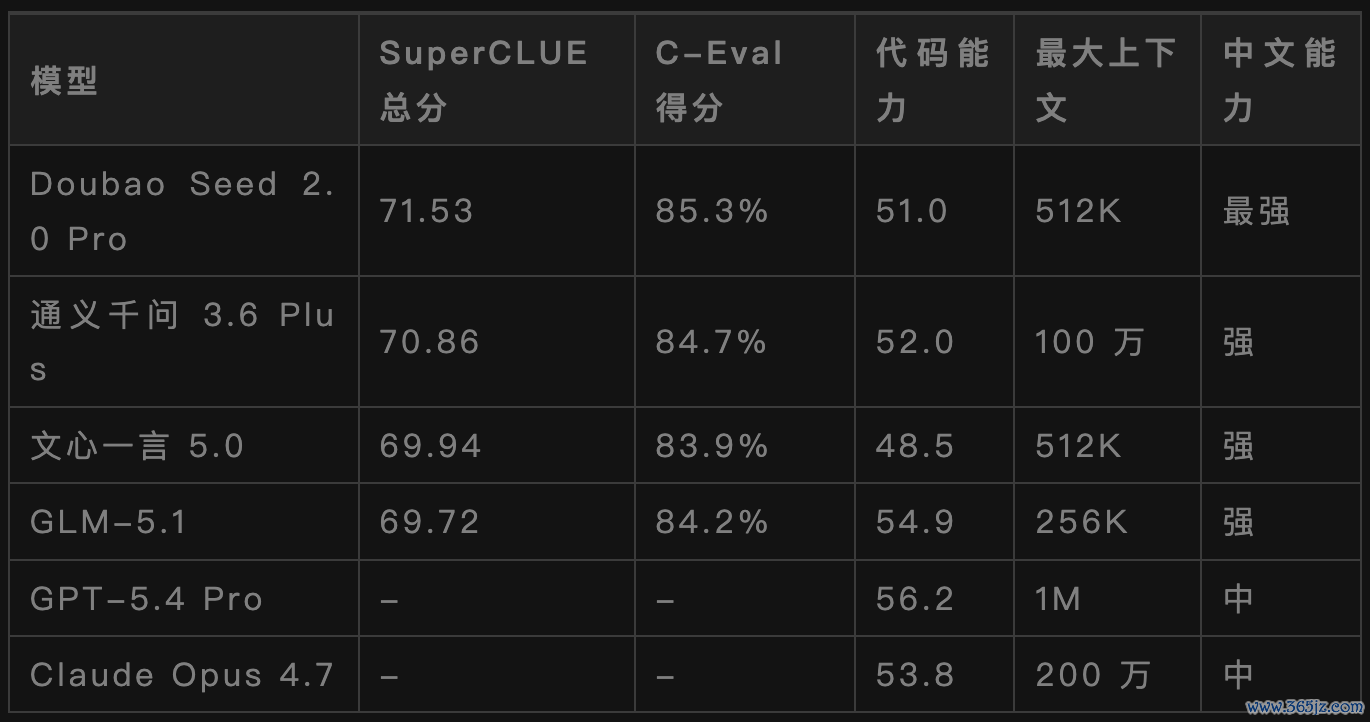
从数据不错看出,国产模子在汉文说明智力上还是全面非凡了外洋模子,在代码智力上也不相凹凸。
2、主流开源模子对比
开源模子的上风是资本低、数据安全、不错摆脱定制。
漏洞是部署复杂、需要专科的运维团队、性能略低于顶级闭源模子。
2026年最受原谅的开源模子有:
Qwen3.5、GLM-5、MiniMaxM2.5、DeepSeek-V4-Pro。
快乐彩app2026世界杯中国官方下载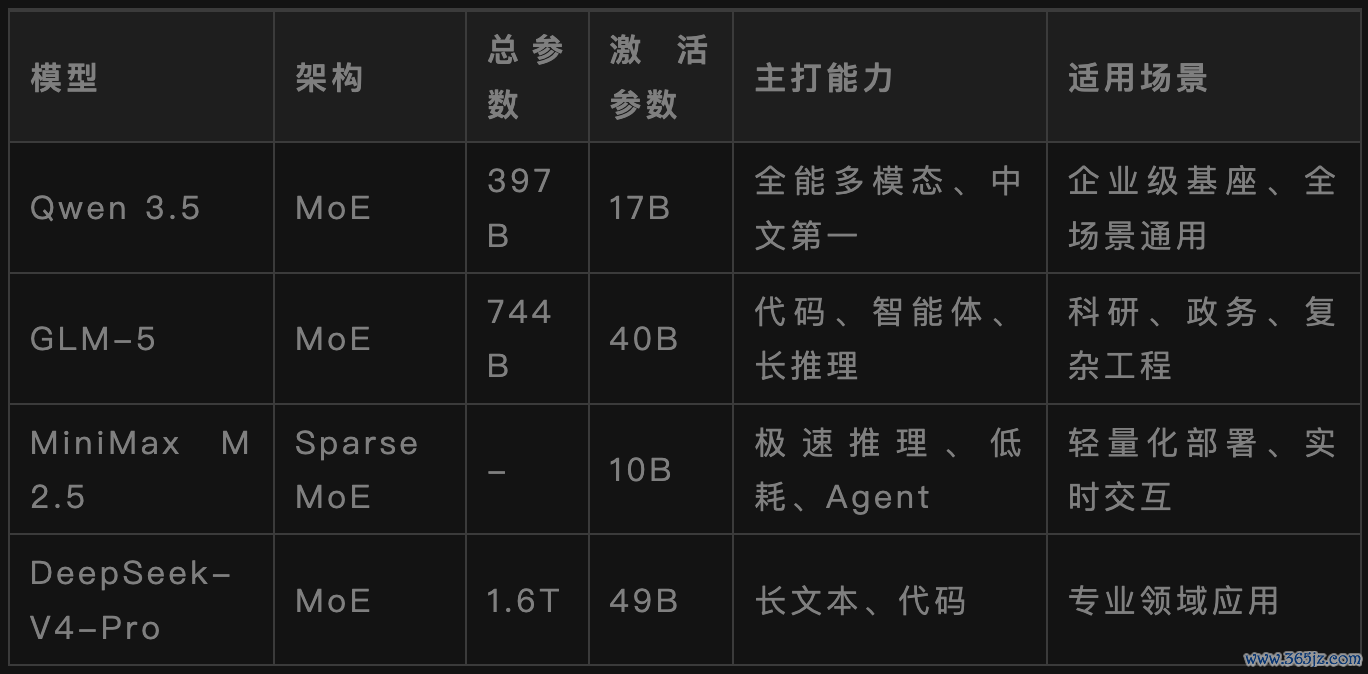
3、范畴适配度:是否需要垂直微调?
通用大模子在垂直范畴的阐扬常常不尽如东谈倡导。
若是你的产物是面向特定行业的(如医疗、法律、金融),那么你需要探究模子是否历程了垂直范畴的微调。
比如:
医疗范畴:不错聘请历程医疗数据微调的Med-PaLM3或者国内的医联大模子
法律范畴:不错聘请北大法宝大模子或者法大的法大模子
金融范畴:不错聘请同花顺大模子或者恒生电子的金融大模子
03资本对比:算明晰这笔账
大模子的资本是好多公司最眷注的问题。
你需要从两个方面对比资本:推理资本和算力资本。
1、推理资本:API调用vs自建GPU集群
这是最中枢的资本对比,我给你算一笔账:
假定你的产物每天需要措置5万次复杂的业务申请,平均单次申请包含1000输入Tokens+500输出Tokens,一个月猜测破钞约22.5亿Tokens。
决议一:调用公有云顶级API
前期进入:¥0
Token/猜测运行费:约¥55万/年(按本色流量计费)
机房托管与网罗:¥0
运维与调优东谈主力:0.2FTE(仅需应用层开拓东谈主员,凤凰彩票中国官网入口约¥5万/年)
年总资本:¥60万
决议二:自建特有化机房(70B开源模子,单台8卡H200管事器)
前期进入:约¥200万(硬件及网罗采购)
Token/猜测运行费:约¥9万/年(电费+制冷费)
机房托管与网罗:约¥12万/年
运维与调优东谈主力:2FTE(需要专科大模子部署、推理优化工程师,约¥70万/年)
年总资本:约¥91万/年(不含前期硬件进入)
从这个对比不错看出:
当流量较小时,调用API更合算,因为莫得前期进入和运维资本
当流量填塞大时,自建集群更合算,因为边缘资本很低
2、算力资本:模子参数目与GPU显存干系
模子参数目越大,需要的GPU显存就越多,资本也就越高。
一个简便的对应干系:
7B模子:单张H200GPU
13B模子:单张H200GPU
34B模子:需要2-4张H200GPU
70B模子:需要4-8张H200GPU
175B模子:需要16-32张H200GPU
当今单张英伟达H200GPU的月房钱约6.0-6.6万元东谈主民币。
不错把柄这个数据估算自建集群的算力资本。
3、资本优化技能
这里共享几个行业内常用的资本优化门径:
智能路由
简便任务用小模子,复杂任务用大模子。
比如豪迈的文天职类用7B模子,复杂的推理用70B模子。
这样不错在不停送体验的前提下,镌汰80%的资本。
扫尾缓存
缓存常见查询的扫尾,幸免重迭猜测。
模子量化
将FP32模子量化为FP16或INT8,不错镌汰显存占用,擢升推理速率,同期精度亏空很小(陆续
批量措置
关于非实时任务,不错批量措置申请,提高GPU诳骗率。
04工程化评估:能不可落地才是关键
一个模子再好,若是不可厚实、高效地部署到坐褥环境,那也没用。
需要从三个方面进行工程化评估:
1、部署考证:精度亏空与性能
当把模子从考研环境部署到坐褥环境时,陆续需要进行边幅养息和优化。
最常用的边幅是ONNX(怒放神经网罗交换边幅)。
这时需要作念以下几点考证:
精度亏空
将模子转机为ONNX设施边幅后,精度亏空是否在可接收边界内。
一般来说,FP16量化的精度亏空
推感性能
在坐褥环境下,模子的推理速率和婉曲量是否知足条目。
显存占用
模子在运行时的显存占用是否在你的硬件资源边界内。
2、用具链好意思满性
若是一个模子莫得配套的用具链,那么你需要我方开拓,这会大大加多工程化的难度和资本。
一个好意思满的大模子用具链应该包括:
教唆工程用具:匡助你编写和优化教唆词
评估体系:自动评估模子的性能和成果
模子自动更新:捏续考研Pipeline,让模子不停学习新的数据
监控告警:实时监控模子的运奇迹态、性能和资本
3、风险审查:这些坑一定要避让
大模子应用有好多潜在的风险,你必须在选型阶段就探究到:
最大并发申请量
你的系统能否承受峰值流量?
若是不可,需要假想限流和左迁机制。
考研数据开端正当
模子的考研数据是否有版权问题?
若是有,可能会濒临法律风险。
商用规则
有些开源模子有商用规则,比如不可用于买卖用途,或者需要付费。
无益内容概率及预防灵验性
模子生成无益内容的概率有多大?
是否有灵验的预防措施?
尽头是内容安全问题,在金融、医疗、政务等明锐范畴,这是一票否决项。
终末
针对口试问题,若是你能按照这个框架走动话,口试官一定会对你刮目相看。
因为这证明你不是一个只会鬼话无补的产物司理,而是一个确实懂技巧、懂业务、能落地的AI产物司理。
AI产物司理的中枢价值不是懂若干技巧术语凤凰彩票(中国)官方网站,而是或者在复杂的技巧和业务之间找到均衡点,作念出最优的决策。
